The Secret Math Behind Your Netflix Binge: How Matrices Power Your Recommendations
Ever wondered how Netflix uncannily knows which movie or TV show you'll want to watch next? The answer lies not in mystical algorithms or crystal balls, but in sophisticated mathematical frameworks that have revolutionised how we consume digital content. At the heart of Netflix's recommendation engine lies a fascinating interplay of linear algebra, collaborative filtering, and machine learning—transforming simple user ratings into personalised entertainment experiences for over 260 million subscribers worldwide.

Netflix's exponential growth in users, content, and ratings creates massive computational challenges for recommendation algorithms, requiring sophisticated mathematical solutions.
The Netflix recommendation system represents one of the most successful real-world applications of matrix mathematics in modern computing. What began as a simple collaborative filtering approach during the Netflix Prize competition has evolved into a complex, multi-layered system that processes billions of interactions daily, making split-second decisions about what content to surface to each user.
The Mathematical Foundation: From Ratings to Matrices
The User-Item Matrix Challenge
The fundamental challenge Netflix faces is predicting unknown ratings in a massive, sparse user-item matrix. Imagine a matrix where each row represents a user and each column represents a piece of content. In Netflix's case, this matrix contains over 260 million rows (users) and hundreds of thousands of columns (content pieces), creating a potential 78 trillion data points. However, the reality is far sparser—users typically interact with less than 1% of available content, leaving over 99% of the matrix empty.

User-movie rating matrix showing how different users rate various movie genres, illustrating the sparsity and preference patterns that recommendation systems analyse.
This sparsity presents both a challenge and an opportunity. The challenge lies in making accurate predictions with limited data points. The opportunity comes from the mathematical properties that allow us to uncover latent patterns in user preferences and content characteristics.
Cosine Similarity: Finding Your Digital Doppelgänger
The first breakthrough in collaborative filtering came through cosine similarity, a mathematical measure that quantifies how similar two users are based on their rating patterns. Unlike simple correlation, cosine similarity focuses on the directional relationship between user preference vectors, making it robust to differences in rating scales.
The mathematical formula for cosine similarity between users A and B is:
$$similarity(A,B) = \frac{A \cdot B}{||A|| \times ||B||} = \frac{\sum_{i=1}^{n} A_i \times B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \times \sqrt{\sum_{i=1}^{n} B_i^2}} $$

User similarity matrix showing cosine similarity scores between users, which Netflix uses to identify users with similar taste preferences for collaborative filtering.
This calculation produces a value between -1 and 1, where 1 indicates identical taste, 0 suggests no correlation, and -1 implies opposite preferences. Netflix uses this similarity score to identify users with comparable viewing patterns, creating the foundation for user-based collaborative filtering.
The power of cosine similarity lies in its ability to handle sparse data effectively. Even when two users have rated only a few common items, the algorithm can still compute meaningful similarity scores by focusing on the angle between their preference vectors rather than their magnitude.
Matrix Factorisation: The Netflix Prize Revolution
Singular Value Decomposition (SVD) Breakthrough
The Netflix Prize competition fundamentally changed how recommendation systems approach matrix completion. The winning solution heavily relied on matrix factorisation techniques, particularly Singular Value Decomposition (SVD), which decomposes the sparse user-item matrix into three smaller, dense matrices.

Singular Value Decomposition (SVD) explained with matrix dimensions and properties in a technical presentation slide.
SVD transforms the original rating matrix R into three components:
$$R = U \times \Sigma \times V^T$$
Where:
U represents user factors (latent user preferences)
Σ contains singular values (importance weights)
V^T represents item factors (latent item characteristics)
The mathematical elegance of SVD lies in its ability to capture the most significant patterns in the data while reducing dimensionality. By retaining only the k largest singular values, Netflix can reconstruct an approximation of the original matrix that often reveals hidden relationships between users and content.
Latent Factor Models and Hidden Preferences
The genius of matrix factorisation extends beyond simple dimensionality reduction. Each factor in the decomposed matrices represents a latent characteristic that might correspond to genres, moods, or viewing contexts. For instance, one factor might capture a user's preference for action movies, while another reflects their tendency to watch romantic comedies during weekends.
These latent factors enable Netflix to make predictions even for users with limited rating history. By representing each user and item as a vector in this reduced-dimensional space, the system can compute predicted ratings using simple dot product operations:
$$\hat{r}_{ui} = \vec{p_u} \cdot \vec{q_i}$$
Where
$$\vec{p_u}$$
represents user u's preferences and
$$\vec{q_i}$$
represents item i's characteristics in the latent factor space.
Scaling Challenges: From Theory to Production
Computational Complexity and Real-Time Constraints
While the mathematical foundations are elegant, implementing these algorithms at Netflix's scale presents enormous computational challenges. The complexity of traditional collaborative filtering approaches scales quadratically with the number of users or items, making them impractical for real-time recommendations.
User-based collaborative filtering requires O(U²) operations to compute all pairwise similarities among U users, while item-based filtering needs O(I²) operations for I items. With Netflix's current scale of 260 million users and 300,000 content pieces, these approaches would require computational resources measured in exabytes.
Matrix factorisation techniques like SVD have better scaling properties, with complexity O(min(UI², IU²)), but still face challenges when deployed in production environments requiring sub-second response times. Netflix addresses these challenges through several mathematical and engineering innovations.
Alternating Least Squares (ALS) for Distributed Computing
One key breakthrough came through Alternating Least Squares (ALS), an iterative algorithm that alternates between fixing user factors and optimising item factors, then vice versa. This approach transforms the complex SVD problem into a series of simpler least squares problems that can be solved efficiently in distributed computing environments.
The ALS algorithm updates user factors by solving:
$$\vec{p_u} = \arg\min_{\vec{p_u}} \sum_{i \in I_u} (r_{ui} - \vec{p_u} \cdot \vec{q_i})^2 + \lambda ||\vec{p_u}||^2$$
Where I_u represents items rated by user u, and λ is a regularization parameter to prevent overfitting. The beauty of ALS lies in its parallelizability—each user's factors can be updated independently, making it suitable for distributed systems like Apache Spark.
Advanced Techniques: Neural Collaborative Filtering
Beyond Traditional Matrix Factorisation
While traditional matrix factorisation techniques provided the foundation for Netflix's early success, the company has increasingly adopted neural network approaches to capture more complex, non-linear relationships in user behaviour. Neural Collaborative Filtering (NCF) represents a significant evolution from simple dot product operations to sophisticated deep learning architectures.
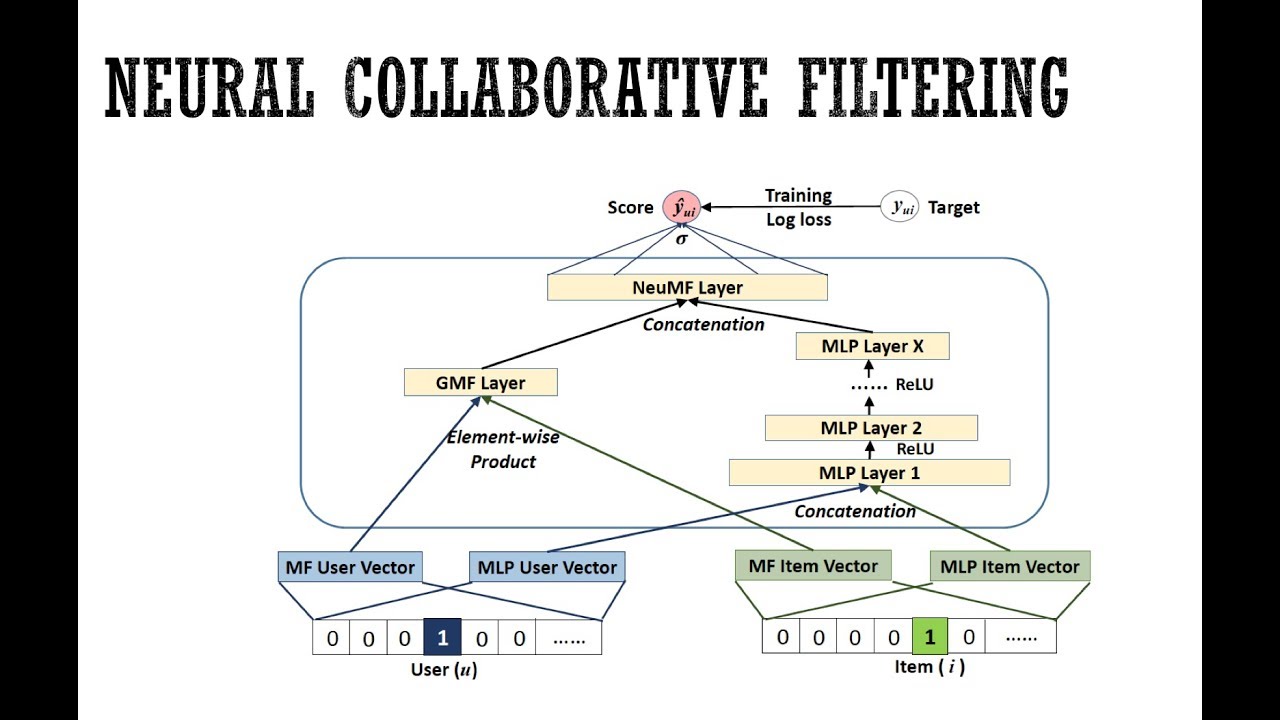
Architecture of neural collaborative filtering combining matrix factorisation and deep learning for recommendations
NCF replaces the linear dot product in traditional matrix factorisation with neural networks capable of learning arbitrary functions from data. The architecture typically combines Generalised Matrix Factorisation (GMF) with Multi-Layer Perceptrons (MLPs) to capture both linear and non-linear user-item interactions.
The NCF framework uses embedding layers to represent users and items as dense vectors, then processes these through multiple hidden layers with non-linear activation functions. This approach can model complex interaction patterns that traditional collaborative filtering might miss, such as seasonal preferences or context-dependent viewing habits.
Foundation Models and the Future of Recommendations
Netflix's latest innovation involves foundation models that can process vast amounts of user interaction data and content metadata simultaneously. These models leverage transformer architectures and semi-supervised learning techniques to create unified representations that can be fine-tuned for specific recommendation tasks.
The foundation model approach addresses several critical challenges in production recommendation systems: cold-start problems for new users and content, entity relationship modelling, and transfer learning across different recommendation contexts. By training on comprehensive user histories rather than limited temporal windows, these models can capture long-term preference evolution and seasonal patterns.
Production Deployment: Engineering Meets Mathematics
Real-Time Inference and Latency Optimisation
Deploying sophisticated mathematical models in production environments requires careful consideration of latency, throughput, and resource utilisation. Netflix's recommendation system must generate personalised suggestions within milliseconds while handling millions of concurrent requests.
The company employs several strategies to optimize inference performance. Pre-computation of user and item embeddings allows for rapid dot product calculations during request time. Approximate nearest neighbour algorithms enable fast similarity searches in high-dimensional embedding spaces. Model compression techniques reduce memory footprint while maintaining prediction accuracy.
Caching strategies play a crucial role in system performance. Netflix maintains multiple layers of caches for user profiles, item metadata, and pre-computed recommendations. These caches are updated incrementally as new user interactions arrive, balancing freshness with computational efficiency.
A/B Testing and Model Evaluation
Mathematical elegance means little without demonstrable business impact. Netflix employs sophisticated A/B testing frameworks to evaluate new recommendation algorithms, measuring not just traditional metrics like Root Mean Square Error (RMSE) but also business-relevant metrics such as user engagement, retention, and content discovery.
The company learned valuable lessons from the Netflix Prize competition: improving RMSE doesn't necessarily translate to better user experience or business outcomes. Modern evaluation frameworks consider multiple objectives simultaneously, including recommendation diversity, novelty, and serendipity.^38
Overcoming Real-World Challenges
The Cold Start Problem and Metadata Integration
One significant challenge in collaborative filtering is the cold start problem—making recommendations for new users with limited interaction history or new content with few ratings. Netflix addresses this through hybrid approaches that combine collaborative filtering with content-based methods using metadata such as genres, cast, directors, and plot keywords.
The mathematical integration of multiple data sources requires careful feature engineering and representation learning. Modern approaches use deep learning to create unified embeddings that capture both interaction patterns and content characteristics. These embeddings enable meaningful recommendations even with sparse interaction data.
Bias and Fairness Considerations
Production recommendation systems must address various forms of bias that can emerge from mathematical models. Popularity bias tends to recommend mainstream content disproportionately, while position bias affects how users interact with recommendation lists. Netflix employs techniques such as inverse propensity weighting and debiasing algorithms to mitigate these effects.
Fairness considerations extend beyond mathematical accuracy to include representation across different content categories, languages, and cultural backgrounds. The company continuously monitors recommendation distribution to ensure diverse content discovery and equitable treatment of different user segments.
Mathematical Innovation and Future Directions
Graph Neural Networks and Complex Interactions
The future of Netflix's recommendation technology lies in more sophisticated mathematical frameworks that can model complex, multi-hop relationships between users, content, and contextual factors. Graph Neural Networks (GNNs) offer promising approaches for capturing these intricate relationships through message passing and attention mechanisms.
These advanced techniques enable modelling of social influence, temporal dynamics, and cross-domain preferences that traditional matrix factorisation approaches cannot capture. The mathematical foundations remain rooted in linear algebra and optimisation theory, but the computational graphs become significantly more complex.
Reinforcement Learning and Long-Term Optimisation
Netflix is increasingly exploring reinforcement learning approaches that optimise for long-term user satisfaction rather than immediate click-through rates. These methods require solving complex mathematical optimisation problems that balance exploration and exploitation while considering the multi-armed bandit nature of content recommendation.
The mathematical framework for reinforcement learning in recommendations involves Markov Decision Processes, policy optimisation, and reward function design. These approaches can adapt recommendation strategies based on user feedback loops and evolving preferences over time.
Conclusion
The mathematics powering Netflix's recommendation system represents a remarkable journey from simple collaborative filtering to sophisticated deep learning architectures. What began with basic matrix operations has evolved into a complex ecosystem of mathematical techniques, including matrix factorisation, neural networks, graph theory, and optimisation algorithms.
The success of Netflix's recommendation system demonstrates the power of applying rigorous mathematical principles to real-world problems at scale. The elegant interplay between linear algebra, machine learning, and distributed computing has created a system that processes billions of user interactions daily while delivering personalised experiences that keep users engaged.
For senior software developers, the Netflix recommendation system serves as a masterclass in mathematical engineering—showing how theoretical concepts from linear algebra and machine learning can be transformed into production systems that impact millions of users worldwide. The evolution from the Netflix Prize's focus on RMSE optimisation to today's multi-objective, context-aware recommendation systems illustrates the importance of aligning mathematical objectives with business goals and user experience.
As the field continues to evolve, the fundamental mathematical principles remain constant: matrix operations for capturing user-item relationships, optimisation algorithms for learning from data, and statistical methods for handling uncertainty and sparsity. The art lies in combining these mathematical building blocks into systems that can operate at unprecedented scale while maintaining the responsiveness and accuracy that users expect from modern recommendation engines.
The secret math behind your Netflix binge is no longer secret—it's a testament to the power of mathematical thinking applied to one of the most challenging problems in modern computing: understanding human preferences and delivering personalised experiences at a global scale.