

Are Your LLM Prompts Burning Cash? A Deep Dive into TOON, the JSON-Alternative for AI
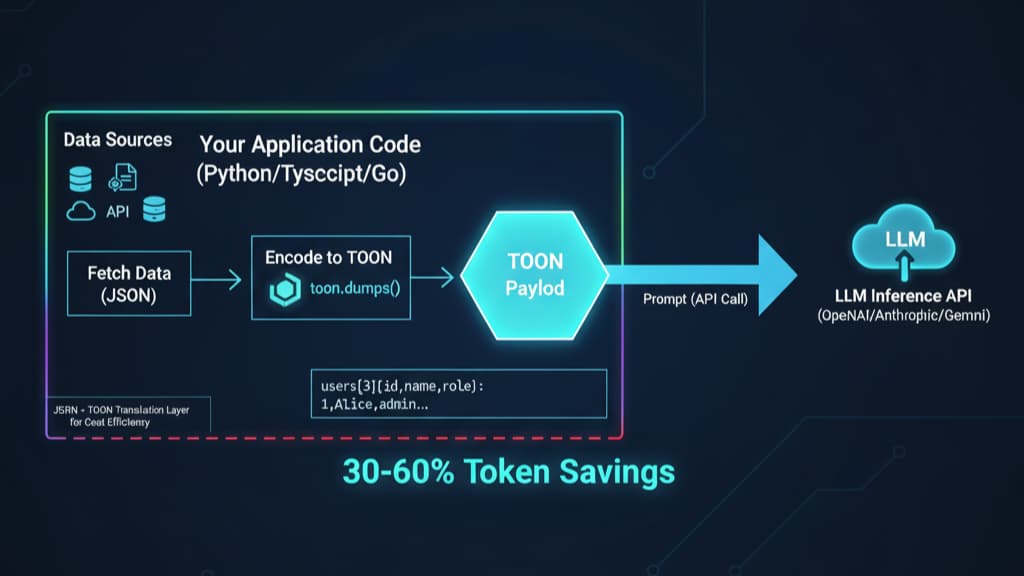
Large Language Models have transformed how we build intelligent systems, but they come with a hidden cost: every character, bracket, and comma in your prompt translates to tokens—and tokens translate to dollars. When you're shipping production AI systems at scale, inefficient data formats aren't just inconvenient; they're a direct hit to your bottom line.
Enter TOON (Token-Oriented Object Notation), a purpose-built serialisation format that achieves 30-60% token reduction compared to JSON while maintaining full semantic fidelity. This isn't just another data format—it's a paradigm shift in how we structure data for LLM consumption.
The Token Economics Problem
Modern LLM APIs charge per token processed. GPT-4o processes approximately 6 characters per token on average. When you serialize data as JSON, you're paying for structural overhead that provides zero semantic value to the model:
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
This innocent-looking JSON consumes approximately 89 tokens. Every curly brace, square bracket, and repeated key name adds to your bill. At scale—think thousands of API calls daily with complex payloads—this verbosity compounds into substantial costs.
TOON's Architectural Philosophy
TOON borrows YAML's indentation-based structure for nested objects and CSV's tabular format for uniform data rows, then optimizes both specifically for token efficiency in LLM contexts. The format makes three key architectural decisions:
Whitespace over punctuation: Instead of wrapping everything in braces and brackets, TOON uses 2-space indentation to denote hierarchy. This eliminates syntactic noise while maintaining clear structure.
Declarative schemas for tabular data: For arrays of uniform objects, TOON declares the field schema once in a header, then streams row data as comma-separated values. This is where the format shines brightest—eliminating repeated key names in large datasets.
Explicit length markers: Array headers include length indicators [N] that serve as validation guardrails for LLMs during structured output generation.
The same data in TOON:
users[2]{id,name,role}:
1,Alice,admin
2,Bob,user
This representation uses approximately 45 tokens—a 50% reduction.
Technical Specification and Format Rules
TOON's specification (v1.4 as of November 2025) defines a deterministic, lossless JSON representation. Let me break down the core encoding rules:
Object Encoding
Simple objects map to key-value pairs with colon separation:
id: 123
name: Ada
active: true
Nested objects use indentation (exactly 2 spaces per level):
user:
id: 123
profile:
name: Ada
verified: true
Array Formats
TOON supports three array formats depending on structure:
Inline arrays (primitives):
tags[3]: frontend,backend,devops
Tabular arrays (uniform objects with identical primitive fields):
products[3]{sku,qty,price}:
A1,2,9.99
B2,1,14.50
C3,5,7.25
This is TOON's killer feature. The tabular format requires all objects to have identical key sets with primitive values only. Field order doesn't matter during encoding, but the header establishes column order.
List arrays (non-uniform or nested structures):
items[2]:
- id: 1
nested:
data: value1
- id: 2
nested:
data: value2
Delimiter Options
TOON supports three delimiters: comma (default), tab (\t), and pipe (|). Alternative delimiters can yield additional token savings depending on the tokenizer:
// Tab-delimited (often more efficient for certain tokenizers)
users[2 ]{id name role}:
1 Alice admin
2 Bob user
The delimiter choice adapts quoting rules automatically—strings containing the active delimiter get quoted, while other characters remain safe.
Quoting Strategy
TOON employs minimal quoting to maximize token efficiency:
Keys: Unquoted if they match the pattern
^[a-zA-Z_][a-zA-Z0-9_.]*$. Everything else requires quotes.String values: Only quoted when containing leading/trailing spaces, the active delimiter, colons, quotes, backslashes, or control characters.
Special cases: Empty strings (
""), numeric-only keys ("123"), and keys with hyphens/brackets get quoted.
This approach eliminates unnecessary quotes that most formats apply universally.
Type System
TOON maps JSON types deterministically:
Numbers: Decimal form, no scientific notation.
NaNand±Infinitybecomenull.Booleans: Literal
true/falseNull: Literal
nullDates: Converted to ISO strings with quotes
BigInt: Decimal digits without quotes
Non-serializable values (functions, symbols, undefined): Convert to
null
Performance Benchmarks: Real-World Token Savings
The official TOON repository includes comprehensive benchmarks across multiple datasets and LLM models. Let me highlight the critical findings:
Token Efficiency by Dataset Type
Uniform tabular data (GitHub repositories, 100 records):
JSON: 15,145 tokens
TOON: 8,745 tokens
Savings: 42.3%
Time-series analytics (180 days):
JSON: 10,977 tokens
TOON: 4,507 tokens
Savings: 58.9%
Deeply nested configuration:
JSON (compact): 574 tokens
TOON: 666 tokens
Overhead: 16%
This last example is crucial: TOON is not optimal for deeply nested, non-uniform structures. The indentation overhead exceeds JSON's bracket-based nesting. Understanding when to use TOON is as important as knowing how.
LLM Comprehension Accuracy
Token efficiency is meaningless if models can't parse the format. The benchmark tested 4 models (GPT-5 Nano, Claude Haiku, Gemini Flash, Grok) across 209 data retrieval questions:
TOON accuracy: 86.6% (135/159 correct)
JSON accuracy: 83.2% (130/159 correct)
Token reduction: 46.3%
TOON actually improves model accuracy. The explicit structure—array lengths, field declarations—helps models parse and validate data more reliably than JSON's free-form structure.
Implementation Architecture
TOON implementations follow a consistent encoder/decoder architecture across languages. Let's examine the JavaScript/TypeScript reference implementation:
Encoding Algorithm
The encoder performs a depth-first traversal of the input object:
Type dispatch: Determine if the value is primitive, object, or array
Array classification: For arrays, check if all elements are uniform objects with primitive fields
Schema extraction: If tabular, extract common keys from the first object
Row serialization: Stream values in column order, applying quoting rules
Indentation tracking: Maintain depth counter for nested structures
The key optimization is the tabular detection algorithm, which must validate:
All array elements are objects (not primitives or mixed types)
Identical key sets across all objects (order-independent comparison)
All values are primitives (no nested objects or arrays)
This runs in O(n·m) time where n is array length and m is average key count, but it's a one-time cost that enables massive token savings downstream.
Decoding State Machine
The decoder implements a line-based parser with context-aware state:
# Pseudo-code state machine
state = {
'depth': 0, # Current indentation level
'context_stack': [], # Parent object contexts
'array_header': None, # Active array metadata
'delimiter': ',' # Active delimiter for current scope
}
for line in input.split('\n'):
depth = count_leading_spaces(line) // 2
content = line.strip()
if is_array_header(content):
parse_array_header(content) # Extract [N]{fields}:
elif is_key_value(content):
parse_key_value(content)
elif is_tabular_row(content):
parse_row_with_schema(content, state.array_header.fields)
The parser maintains a context stack to track nested objects and respects delimiter scope changes from array headers.
Memory Efficiency
TOON's encoding is designed for streaming with pre-allocated buffers. Unlike JSON stringify, which often builds the entire output string in memory before returning, TOON encoders can write directly to streams for large datasets.
The reference implementation uses:
Serialisation: O(n) time and O(d) space, where d is the max nesting depth
Deserialization: O(n) single-pass parsing with O(d) context stack
Token reduction: 30-60% for typical structured data
Production Deployment Patterns
TOON is designed as a translation layer. You don't rewrite your application to use TOON internally—you convert at the LLM boundary:
// Application logic uses JSON
const userData = await db.query('SELECT * FROM users LIMIT 100');
// Convert to TOON before LLM call
import { encode } from '@toon-format/toon';
const toonData = encode(userData);
const response = await llm.chat({
messages: [{
role: 'user',
content: `Analyze this data:\n\`\`\`toon\n${toonData}\n\`\`\``
}]
});
When to Use TOON
✅ Ideal use cases:
Product catalogues with uniform schemas
Transaction logs and event streams
Time-series data (sensor readings, metrics)
Batch inference on tabular data
User profiles, inventory records, and any CRUD data
100+ records with consistent field structure
❌ Avoid TOON for:
Deeply nested configuration objects
Irregular data with varying field sets per record
Tiny payloads (<50 tokens)
Public API contracts requiring standardization
Complex nested object graphs
Architecture Mandate
For maximum efficiency, flatten before encoding:
// Nested JSON - inefficient for TOON
const nested = {
orders: [{
customer: { id: 1, name: 'Alice' },
items: [{ sku: 'A1', qty: 2 }]
}]
};
// Flatten to uniform schema
const flattened = {
orders: [{
customer_id: 1,
customer_name: 'Alice',
item_sku: 'A1',
item_qty: 2
}]
};
encode(flattened); // Much more efficient
LLM Prompt Engineering with TOON
TOON shines when you show, not tell. The format is self-documenting—models parse it naturally after seeing one example:
You are a data analyst. Here's the sales data:
sales{date,product_id,revenue,units}:
2025-01-01,P001,1250.50,45
2025-01-01,P002,890.25,23
...
Calculate total revenue by product. Output as TOON.
For structured output generation, prefill the header:
Generate a TOON array of the top 5 products:
products[5]{product_id,name,revenue}:
The model fills rows instead of regenerating keys, reducing both tokens and hallucination risk. The explicit length marker [5] constrains output length.
Multi-Language Ecosystem
TOON has official and community implementations across languages:
TypeScript/JavaScript: Reference implementation (
@toon-format/toon)Python:
toon-pythonpackageRust:
serde_toonwith Serde integrationGo:
toon-goDart:
toonpackage for Flutter.NET:
toon-dotnetElixir:
toon_exwith Telemetry supportGleam:
toon_codec
All implementations target 100% compatibility with the official specification test fixtures.
Limitations and Trade-offs
TOON isn't a silver bullet. Understanding its constraints is crucial:
Ecosystem maturity: JSON has decades of tooling, debugging support, and ecosystem integration. TOON is emerging.
Nested structure overhead: For deeply nested objects, indentation-based encoding can exceed JSON's compact bracket nesting.
Learning curve: Teams need to understand when tabular format applies. Not all data structures are good candidates.
Debugging: Standard JSON viewers don't parse TOON. You need TOON-specific formatters (available as CLI tools).
Non-LLM contexts: TOON is optimized for LLM tokenizers. For traditional APIs, file storage, or browser apps, stick with JSON.
Future Directions
The TOON specification is under active development with a growing community. Key areas of evolution:
Tokenizer-specific optimisation: Different LLMs use different tokenizers (BPE, SentencePiece, WordPiece). Future work may provide tokenizer-specific delimiter recommendations.
Streaming protocols: Extending TOON for real-time data streams with incremental parsing.
Compression integration: Combining TOON with binary encoding schemes for maximum efficiency.
IDE tooling: Language servers, syntax highlighting, and debugging tools to match JSON's ecosystem.
Conclusion: The Economic Imperative
Token optimisation isn't premature optimisation. It's an economic necessity. At production scale, a 50% token reduction translates directly to halving your LLM API costs. For companies processing millions of API calls monthly, this is the difference between a sustainable business model and burning cash.
TOON represents a fundamental rethinking of data serialisation for the AI era. By eliminating syntactic redundancy and leveraging tabular structure where appropriate, it achieves the rare combination of improved efficiency and improved model accuracy.
The format isn't trying to replace JSON everywhere—it's purpose-built for one critical use case: passing structured data to LLMs as efficiently as possible. In that context, it excels.
As LLM context windows grow and token pricing evolves, formats like TOON will become standard practice for production AI engineering. The question isn't whether to optimise token usage—it's whether you can afford not to.
Resources:
Official Specification: github.com/toon-format/spec
Reference Implementation: github.com/toon-format/toon
Interactive Playground: toonformat.dev (test conversions and count tokens)
Benchmarks: github.com/johannschopplich/toon/tree/main/benchmarks
